I decided to wind down adam. The LND software has recently become unstable and unreliable and I have limited time to resolve the issues. I will do some inspection and cleanup during the next few months and post a housekeeping report here for the interested. Some of the issues I observed are channel closings with stuck funds which needs manual handling and is very time consuming.
New Node: Adam
Meet adam.masterofpearls.net. Like in the saga, aka Takezo Kensei, it has great healing powers. The new node has a mirror configuration powered by zfs, which works even cross platform for data replication onto a storage server.
As shown in the following figure, the lightning node is running as a virtual machine on a zfs root partition, consisting of a ZVOL disk provided by the host system and one disk provided via iscsi on a storage server. The ZVOL disk itself is located on a mirrored zfs pool on the host system, which has active spares in case of disk failures.
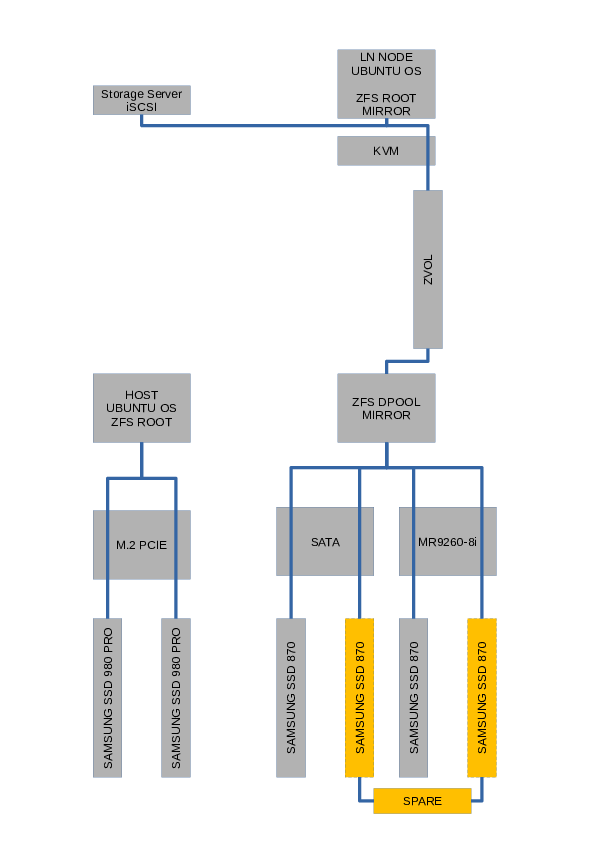
Adam will replace the role of hiro and ando in one node. This means it will provide the same onboarding characteristics as ando with unmanaged liquidity and zero fees (channels <=8M). Bigger channels for routing to the wider network will be subject to a routing fee schedule and managed liquidity, like on hiro. Liquidity protection on the channels will the universal. Check the nodes page for details.
Recovery Hiro/Ando
Today: 2022-12-25
Recovery steps for hiro and ando.
bitcoin v22.0
LND version v0.15.5
chantools v0.10.6
1) The ddrescue yielded channel.db files for both nodes ando and hiro. Starting the node with these channel.db files reveals the corruption [1].
2) chantools compactdb command failed
3) chantools summary command succeeded, yielding the correct description of 627 channels for ando and 134 channels for hiro with the latest local and remote balances.
4) chantools forceclose (without publish) succeeded, yielding the correct listing of 580 closed channels and 47 open channels for ando, 129 closed channels and 5 open channels for hiro.
5) chantools walletinfo was used to extract the BIP32 HD root key
6) chantools forceclose (with publish) with the BIP32 HD root key was used to generate and submit all remaining force close transactions
7) Waiting for the timeouts to move all the remaining balances off the nodes
8) Recovery succeeded 100%
Finishing putting together the infrastructure for the new node.
Footnotes:
[1]
panic: freepages: failed to get all reachable pages (page 0: invalid type: unknown<00>)
goroutine 322 [running]:
go.etcd.io/bbolt.(DB).freepages.func2() go.etcd.io/bbolt@v1.3.6/db.go:1056 +0x99 created by go.etcd.io/bbolt.(DB).freepages
go.etcd.io/bbolt@v1.3.6/db.go:1054 +0x1ea
Attempting automatic RPC configuration to bitcoind
Automatically obtained bitcoind’s RPC credentials
2022-12-21 19:15:25.746 [INF] LTND: Version: 0.15.5-beta commit=v0.15.5-beta, build=production, logging=default, debuglevel=info
2022-12-21 19:15:25.746 [INF] LTND: Active chain: Bitcoin (network=mainnet)
2022-12-21 19:15:25.753 [INF] RPCS: RPC server listening on 127.0.0.1:10010
2022-12-21 19:15:25.758 [INF] RPCS: gRPC proxy started at 127.0.0.1:8081
2022-12-21 19:15:25.758 [INF] LTND: Opening the main database, this might take a few minutes…
2022-12-21 19:15:25.758 [INF] LTND: Opening bbolt database, sync_freelist=false, auto_compact=false
panic: freepages: failed to get all reachable pages (page 0: invalid type: unknown<00>)
Crash Hiro/Ando
Today: 2022-12-21
On December 6, 2022 the system running both nodes, hiro and ando, experienced a crash due to the system partition having I/O errors. Attempts to copy data off the SSD, sector by sector, revealed the origin to be low level damage, most likely bad sectors. This low level damage caused the whole SSD to eject and take down the running system as well.
A) Notes on SSD:
a) Samsung EVO 850, MZ-75E2T0, acquired 2018, hardly used until 8/2022 when I moved ando and hiro to a new system. Total TB written ~ 30 TB.
b) Visual inspection of the SSD chips and board shows no signs of wear.
c) Using dd to copy data sector by sector works for GB sections 0-152GB at full speed and then again for 450GB-2000GB. When trying 153GB-450GB, the read out hits I/O errors at least every 5GB. The errors cause the firmware to shutdown the drive, requiring a power cycle to get it back to being responsive.
d) Mounting the drive and the file systems allowed me to copy all files, except the channel.db files of both nodes. This suggests that the channel.db file is scattered among many sectors within the region 152GB-450GB.
e) After a few days of applying ddrescue [1] to the failed drive, it finally finished [2]. Due to the drive ejecting after each I/O error (firmware, capacity change to 0), a full system restart was required. This was done via ‘ipmitool power cycle’ embedded into a script which got executed via cronjob/reboot technique. The script contained a sleep command to allow a time window for manual intervention. This worked, because the mainboard is server grade with a BMC system.
B) Notes on lightning:
a) SCB with DLP works to a degree. About 90% of channels got settled almost immediately after the node software was initialized with the channel.backup file and the seed.
b) Of the remaining channels, some have issued a manual force close either by themselves or after sending a request message via lightningnetwork.plus
c) There are some old channels where the peers have been offline for a long time or for which there is no clear contact information. These are zombie channels. Waiting a while for them to come back online. After a long waiting period I can use an old channel.db file to close out those zombies manually. There is a risk of triggering a penalty this way and loose all funds.
d) I correlated the risks for hiro and ando by putting them on the same SSD. I will likely have to use chantools to create a fake channel.db to close out the channels between them if I can’t recover from the corrupt channel.db file.
C) Conclusions:
a) Negligence bites. I had the infrastructure and knowledge for proper real-time data replication in place for a while, but I procrastinated.
b) Based on prior knowledge and some comments in the Twitter feed, the path forward is to have a ZFS mirror configuration (raid 1) to handle points of failure. For each layer have an active spare ready for automatic failover. Will post schematics for the new system when finished.
c) For automatic failover, a mirror onto another system is required which may be achieved via a replicating db technology (Postgres) or something like DRBD.
d) A mirror onto a system in another building should be considered as well to mitigate the risk of fire taking down the main system with its respective mirrors.
e) While not perfect, a backup schedule for the channel.db file allows better risk management for channels which are not responsive and require force close from an older commitment transaction. This should be kept in mind as a last resort option. There are risk-benefit aspects of doing this which depends on the anticipated channel states and on who the initiator of the channel was – it’s complex.
f) A social platform for communication is important. Lightning has no native node to node messaging system.
D) Fun facts
a) Server mainboards with BMC really helps dealing with faulty equipment. ASRock really did a great job with their web interface. Power cycles with a click of a button.
b) UUID > /dev/sdX. The later can swap around if you’re not careful
Footnotes:
[*1]
ddrescue -X 1 -c 1 -d -Z 10485760 –pause-on-error=1 –mapfile-interval=1,5 -vv /dev/sdc1 sdc1.ddr mapfile
[*2]
GNU ddrescue 1.23
About to copy 2000 GBytes from ‘/dev/sdc1’ UNKNOWN to ‘sdc1.ddr’ (2000397868032)
Starting positions: infile = 0 B, outfile = 0 B
Copy block size: 1 sectors Initial skip size: 39168 sectors
Sector size: 512 Bytes
Max read rate: 10485 kB/s
Pause on error: 1s
Direct in: yes Direct out: no Sparse: no Truncate: no
Trim: yes Scrape: yes Max retry passes: 0
Press Ctrl-C to interrupt
Initial status (read from mapfile)
rescued: 2000 GB, tried: 106110 kB, bad-sector: 34619 kB, bad areas: 642
Current status
ipos: 450058 MB, non-trimmed: 0 B, current rate: 5482 kB/s
opos: 450058 MB, non-scraped: 0 B, average rate: 5957 kB/s
non-tried: 0 B, bad-sector: 34619 kB, error rate: 0 B/s
rescued: 2000 GB, bad areas: 642, run time: 11s
pct rescued: 99.99%, read errors: 0, remaining time: 0s
time since last successful read: n/a
Finished